Ρυθμίσεις Ανίχνευσης Κίνησης στο Swing Catalyst
Εισαγωγή
Αυτό το άρθρο περιγράφει πώς να ρυθμίσετε και να διαμορφώσετε τη λειτουργία Ανίχνευσης Κίνησης στο Swing Catalyst. Αυτή η λειτουργία ενδέχεται να μην είναι διαθέσιμη για όλους τους τύπους άδειας. Παρακαλούμε ανατρέξτε στις Συχνές Ερωτήσεις για την Ανίχνευση Κίνησης για περισσότερες πληροφορίες.
Απαιτήσεις
- Τα στοιχεία πρέπει να εγκατασταθούν στον κατάλογο στοιχείων.
Ο υπολογιστής σας πρέπει να πληροί τις προδιαγραφές PC που συνιστούμε. Το πιο σημαντικό είναι ότι η κάρτα γραφικών πληροί τις συστάσεις μας.
Διαμόρφωση
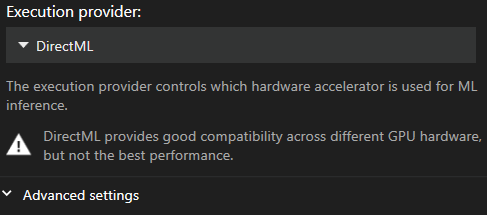
Οι ρυθμίσεις Ανίχνευσης Κίνησης βρίσκονται στο κύριο μενού Ρυθμίσεων, στην ενότητα “Video & Capture”. Από εδώ μπορείτε να επιλέξετε ή να αλλάξετε τους παρόχους εκτέλεσης και το μέγεθος παρτίδας.
Συνιστούμε μέγεθος παρτίδας μεταξύ 12 και 24, ανάλογα με τον αριθμό των ενεργών/ενεργοποιημένων καμερών σας.
Συνιστώμενος Πάροχος Εκτέλεσης
NVIDIA
NVIDIA RTX 3060 ή νεότερη GPU -> TensorRT
Αν το TensorRT δεν λειτουργεί, δοκιμάστε CUDA
Άλλες κάρτες γραφικών
- DirectML
Η προεπιλογή είναι το DirectML καθώς είναι ο πιο συμβατός πάροχος. Δυστυχώς είναι επίσης ο πιο αργός.
Κατά τη διάρκεια δοκιμών αξιολόγησης διαπιστώσαμε ότι το TensorRT είναι ο πιο αποδοτικός από τους παρόχους εκτέλεσης.
Το TensorRT είναι κατά μέσο όρο (35-45% ταχύτερο από το DirectML, 20-25% ταχύτερο από το CUDA)
Το CUDA προσφέρει μέτριες βελτιώσεις σε σχέση με το DirectML (10-12% κατά μέσο όρο)
Το CUDA χρησιμοποιεί σημαντικά περισσότερη μνήμη GPU (VRAM) από το TensorRT. Παρακαλούμε δοκιμάστε να μειώσετε το μέγεθος παρτίδας αν χρησιμοποιείτε CUDA
Λήψη στοιχείων
Αν επιλέξετε ένα στοιχείο που δεν είναι ήδη εγκατεστημένο, θα σας ζητηθεί να το κατεβάσετε.
Για να χρησιμοποιήσετε TensorRT ή CUDA θα πρέπει να κατεβάσετε πρώτα τα αντίστοιχα στοιχεία.
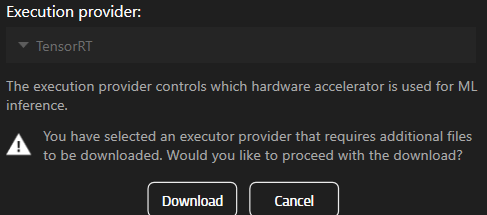
note: Αυτή η λειτουργία είναι διαθέσιμη μόνο στην έκδοση 25.2.
Συνιστώμενο Μέγεθος Παρτίδας
Σύμφωνα με τις δοκιμές μας, μεγαλύτερα μεγέθη παρτίδας παρέχουν καλύτερη Απόδοση. Συνιστούμε μέγεθος παρτίδας μεταξύ 16 και 24 για μια τυπική Προετοιμασία 2-3 καμερών. Αν χρησιμοποιείτε παράλληλα άλλο λογισμικό που απαιτεί πόρους γραφικών, ενδέχεται να είναι ωφέλιμο να δοκιμάσετε μικρότερο μέγεθος παρτίδας. Σε τελική ανάλυση, το βέλτιστο μέγεθος παρτίδας μπορεί να εξαρτάται από τη ροή εργασίας σας και από το είδος των προγραμμάτων που εκτελούνται παράλληλα με το Swing Catalyst.
Προηγμένες Ρυθμίσεις
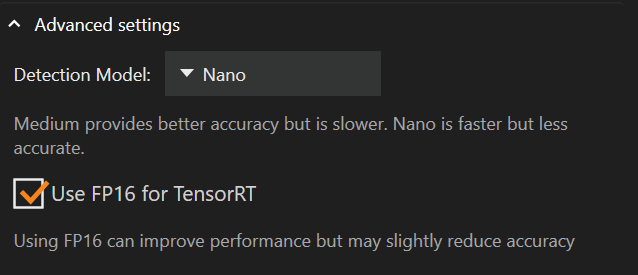
Κάτω από τις ρυθμίσεις παρόχου εκτέλεσης βρίσκονται οι προηγμένες ρυθμίσεις, όπου μπορείτε να αλλάξετε το μοντέλο ανίχνευσης ή να ενεργοποιήσετε το “FP16”.
Η αλλαγή του μοντέλου ανίχνευσης από Medium σε Nano μπορεί να μειώσει τη χρήση μνήμης της κάρτας γραφικών σας και να βελτιώσει την Απόδοση, με κόστος στην ακρίβεια.
Αν δυσκολεύεστε να επιτύχετε ικανοποιητική ανίχνευση, δοκιμάστε να αλλάξετε το μοντέλο σε Medium, επανεκκινήστε το SwingCatalyst και δοκιμάστε ξανά.
Το προεπιλεγμένο μοντέλο ανίχνευσης είναι το Nano
Η επιλογή “FP16 για TensorRT” δεν είναι επιλεγμένη από προεπιλογή
FP16
Η χρήση FP16 μπορεί να μειώσει τη χρήση μνήμης και να βελτιώσει την Απόδοση (με κόστος στην ακρίβεια).
Κατά τη διάρκεια δοκιμών διαπιστώσαμε ότι το FP16 μπορεί να βελτιώσει την Απόδοση κατά 20-35%.
Ενδέχεται επίσης να παράγει λιγότερο συνεπή αποτελέσματα μεταξύ Εγγραφών σε σύγκριση με την προεπιλογή FP32. Αξίζει να το δοκιμάσετε αν αντιμετωπίζετε προβλήματα Απόδοσης ή αν εξαντλείται η μνήμη σας.
Συγκρίσεις Απόδοσης
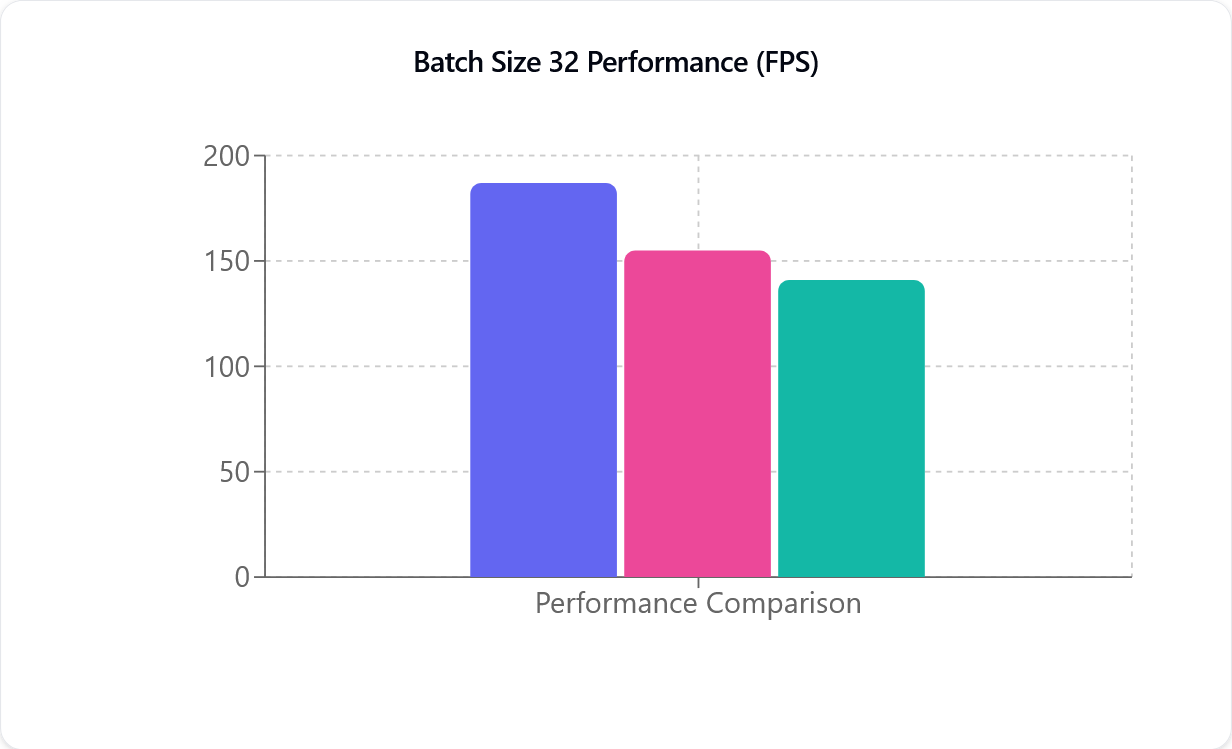
TensorRT (μωβ), CUDA (ροζ) και DirectML (πράσινο), από αριστερά προς τα δεξιά. Ο άξονας Y (FPS) αντιστοιχεί στον αριθμό Πλαισίων ανά Δευτερόλεπτο που το μοντέλο Ανίχνευσης Κίνησης είναι σε θέση να επεξεργαστεί και δεν σχετίζεται άμεσα με τον Ρυθμό Πλαισίων της κάμεράς σας.
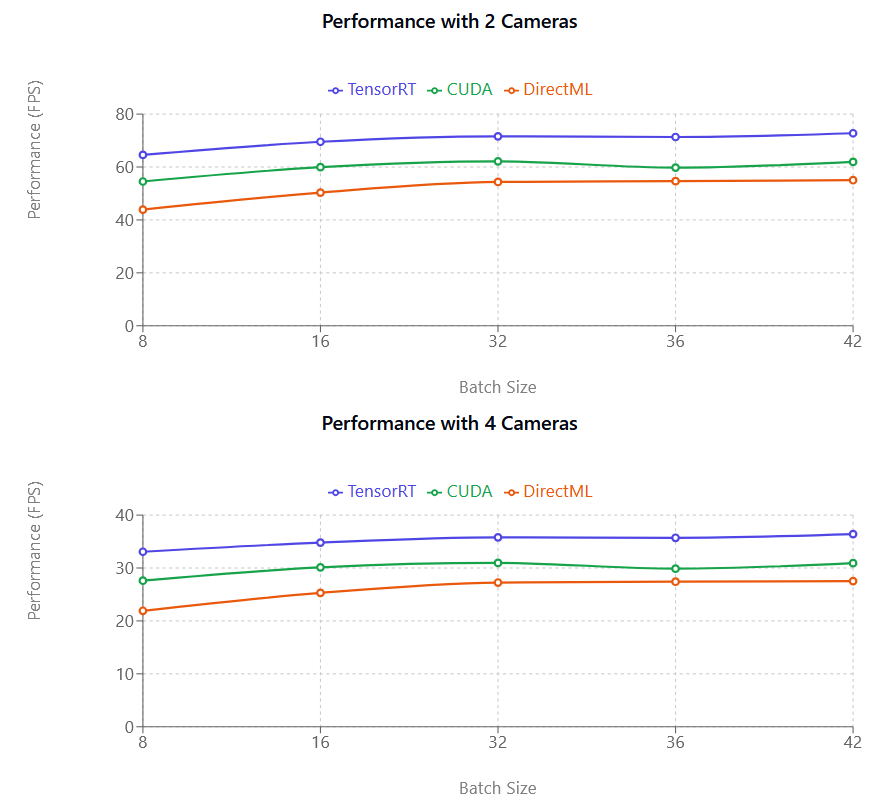
Η Μέτρηση Απόδοσης (FPS) αντιστοιχεί στον αριθμό Πλαισίων ανά Δευτερόλεπτο που επεξεργάζεται το σύστημα· όσο μεγαλύτερος είναι ο αριθμός, τόσο πιο γρήγορα γίνεται η επεξεργασία. Όπως φαίνεται στην παραπάνω εικόνα, τόσο το CUDA όσο και το TensorRT είναι σχεδόν γραμμικά. Για παράδειγμα, μεταβαίνοντας από μία σε δύο κάμερες, η Απόδοση μειώνεται σχεδόν στο μισό. Αυτή η μείωση Απόδοσης είναι λιγότερο αισθητή με νεότερες κάρτες γραφικών NVIDIA.
Τελευταία ενημέρωση: 2025-05-16 | Προβολή στον επίσημο ιστότοπο υποστήριξης