Swing Catalyst मोशन कैप्चर सेटिंग्स
परिचय
यह लेख Swing Catalyst में मोशन कैप्चर कार्यक्षमता को सेटअप और कॉन्फ़िगर करने का तरीका बताता है। यह सुविधा सभी लाइसेंस प्रकारों के लिए उपलब्ध नहीं हो सकती, अधिक जानकारी के लिए कृपया हमारा मोशन कैप्चर FAQ देखें।
आवश्यकताएँ
- कॉम्पोनेंट्स को कॉम्पोनेंट्स डायरेक्टरी में इंस्टॉल किया जाना आवश्यक है।
आपके कंप्यूटर को हमारी PC स्पेसिफिकेशन अनुशंसाओं को पूरा करना होगा, सबसे महत्वपूर्ण यह है कि ग्राफिक्स कार्ड हमारी अनुशंसाओं पर खरा उतरे।
कॉन्फ़िगरेशन
मोशन कैप्चर सेटिंग्स मुख्य Settings मेनू में “Video & Capture” अनुभाग के अंतर्गत मिलती हैं। यहाँ से आप execution providers और batch size का चयन या परिवर्तन कर सकते हैं।
हम आपके सक्रिय / सक्षम कैमरों की संख्या के आधार पर 12 से 24 के बीच batch size की अनुशंसा करते हैं।
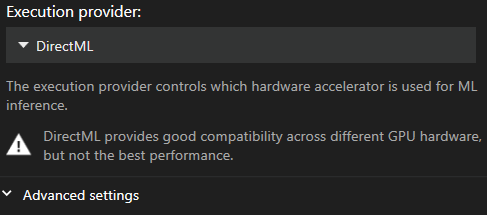
अनुशंसित Execution Provider
NVIDIA
NVIDIA RTX 3060 या नया GPU -> TensorRT
यदि TensorRT काम न करे, तो CUDA आज़माएँ
अन्य ग्राफिक्स कार्ड
- DirectML
डिफ़ॉल्ट DirectML है क्योंकि यह सबसे अधिक संगत provider है। दुर्भाग्यवश यह सबसे धीमा भी है।
बेंचमार्क परीक्षण के दौरान हमने पाया है कि TensorRT सभी execution providers में सबसे अधिक परफॉर्मेंस देता है।
TensorRT औसतन (DirectML से 35-45% तेज़, CUDA से 20-25% तेज़) है
CUDA, DirectML की तुलना में मध्यम सुधार प्रदान करता है (औसतन 10-12%)
CUDA, TensorRT की तुलना में काफी अधिक GPU मेमोरी (VRAM) का उपयोग करता है, यदि आप CUDA उपयोग करते हैं तो कृपया batch size कम करने का प्रयास करें
कॉम्पोनेंट डाउनलोड
यदि आप कोई ऐसा कॉम्पोनेंट चुनते हैं जो पहले से इंस्टॉल नहीं है, तो आपको उसे डाउनलोड करने का संकेत दिया जाएगा।
TensorRT या CUDA उपयोग करने के लिए आपको पहले कॉम्पोनेंट्स डाउनलोड करने होंगे।
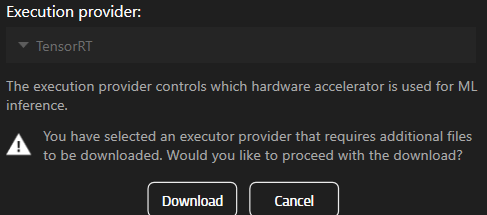
note: यह सुविधा केवल संस्करण 25.2 में उपलब्ध है।
अनुशंसित Batch Size
हमारे परीक्षण के अनुसार बड़े batch size बेहतर परफॉर्मेंस देते हैं। एक सामान्य 2-3 कैमरा सेटअप के लिए हम 16 से 24 के बीच batch size की अनुशंसा करते हैं। यदि आप एक ही समय में कोई अन्य सॉफ़्टवेयर चला रहे हैं जिसे ग्राफिक्स संसाधनों की आवश्यकता है, तो कम batch size आज़माना फायदेमंद हो सकता है। अंततः सर्वोत्तम batch size आपके कार्य-प्रवाह और SwingCatalyst के साथ-साथ चलाए जा रहे प्रोग्रामों पर निर्भर कर सकती है।
उन्नत सेटिंग्स
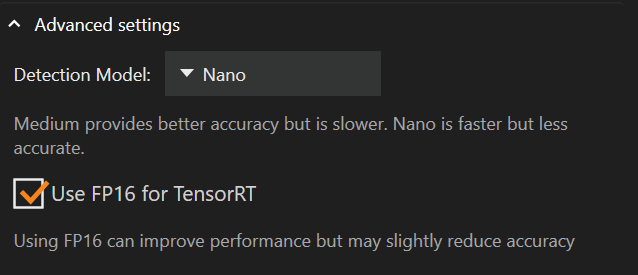
Execution provider सेटिंग्स के नीचे उन्नत सेटिंग्स हैं जहाँ आप detection model बदल सकते हैं या “FP16” सक्षम कर सकते हैं।
Detection model को Medium से Nano में बदलने से आपके ग्राफिक्स कार्ड की मेमोरी उपयोग कम हो सकती है और परफॉर्मेंस में सुधार हो सकता है, लेकिन इससे सटीकता कम होगी।
यदि आपको अच्छी detection प्राप्त करने में कठिनाई हो रही है, तो model को Medium में बदलने, SwingCatalyst को पुनः आरंभ करने और दोबारा प्रयास करने की कोशिश करें।
डिफ़ॉल्ट detection model Nano है
“TensorRT के लिए FP16” डिफ़ॉल्ट रूप से अनचेक है
FP16
FP16 का उपयोग करने से मेमोरी उपयोग कम हो सकता है और परफॉर्मेंस में सुधार हो सकता है (सटीकता की कीमत पर)।
परीक्षण के दौरान हमने पाया है कि FP16 परफॉर्मेंस को 20-35% तक सुधार सकता है।
यह डिफ़ॉल्ट FP32 की तुलना में रिकॉर्डिंग के बीच अधिक असंगत परिणाम भी दे सकता है। यदि आपको परफॉर्मेंस में समस्या हो रही है या मेमोरी कम पड़ रही है तो इसे आज़माना उचित हो सकता है।
परफॉर्मेंस तुलना
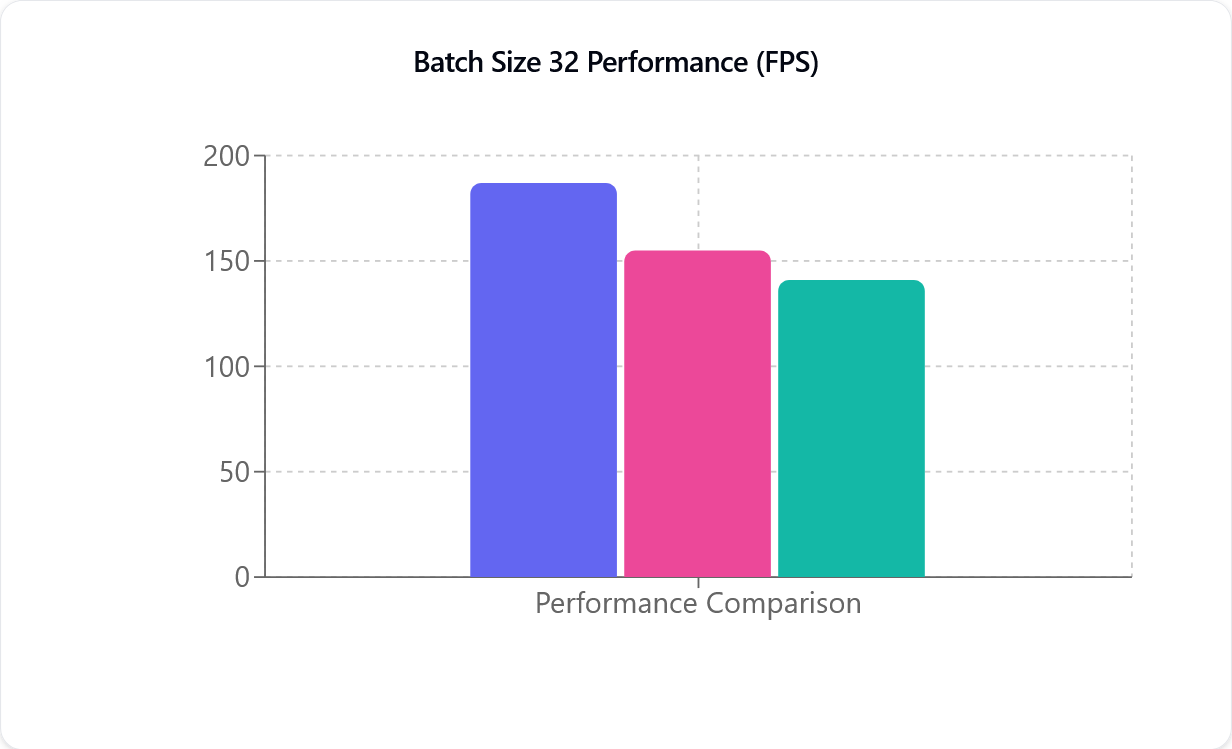
TensorRT (बैंगनी), CUDA (गुलाबी), और DirectML (हरा), बाएँ से दाएँ। Y अक्ष (FPS) मोशन कैप्चर मॉडल द्वारा प्रति सेकंड प्रोसेस किए जा सकने वाले फ्रेम की संख्या है और यह सीधे आपके कैमरे की फ्रेम दर से संबंधित नहीं है।
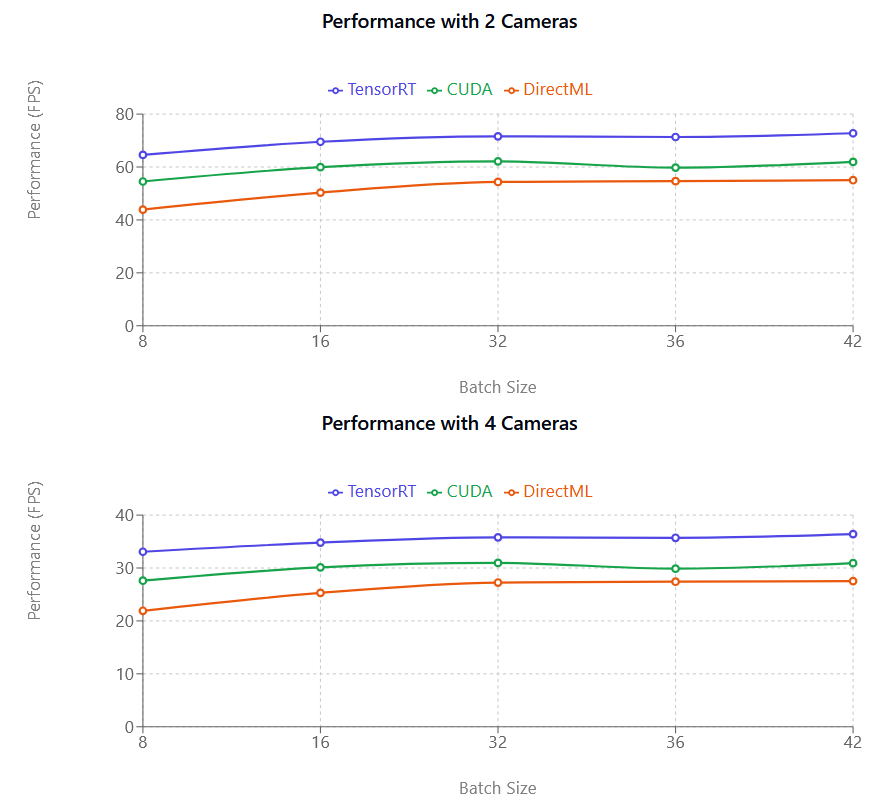
परफॉर्मेंस मापक (FPS) यह दर्शाता है कि प्रति सेकंड कितने फ्रेम प्रोसेस किए जाते हैं — संख्या जितनी अधिक, प्रोसेसिंग उतनी तेज़। जैसा कि ऊपर के चित्र में दिखाया गया है, CUDA और TensorRT दोनों लगभग रैखिक हैं। उदाहरण के लिए, एक से दो कैमरे होने पर परफॉर्मेंस लगभग आधी हो जाती है। यह परफॉर्मेंस कमी नए NVIDIA ग्राफिक्स कार्ड के साथ कम ध्यान देने योग्य होती है।
अंतिम अपडेट: 2025-05-16 | आधिकारिक सपोर्ट साइट पर देखें