Impostazioni Motion Capture di Swing Catalyst
Introduzione
Questo articolo descrive come configurare la funzionalità Motion Capture all’interno di Swing Catalyst. Questa funzione potrebbe non essere disponibile per tutti i tipi di licenza; consulta le nostre FAQ su Motion Capture per ulteriori informazioni.
Requisiti
- I componenti devono essere installati nella directory dei componenti.
Il tuo computer deve soddisfare i requisiti PC da noi consigliati; il requisito più importante è che la scheda grafica rispetti le nostre raccomandazioni.
Configurazione
Le impostazioni di Motion Capture sono accessibili dal menu principale Impostazioni, nella sezione “Video e Acquisizione”. Da qui puoi selezionare o modificare i provider di esecuzione e la dimensione del batch.
Consigliamo una dimensione del batch compresa tra 12 e 24, a seconda del numero di telecamere attive / abilitate.
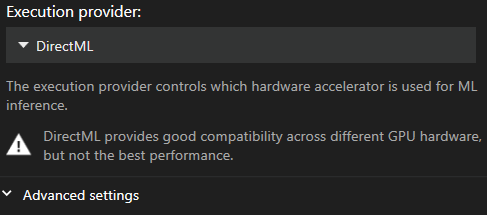
Provider di esecuzione consigliato
NVIDIA
GPU NVIDIA RTX 3060 o più recente -> TensorRT
Se TensorRT non funziona, prova CUDA
Altre schede grafiche
- DirectML
L’impostazione predefinita è DirectML poiché è il provider più compatibile. Purtroppo è anche il più lento.
Nelle nostre prove di benchmark abbiamo riscontrato che TensorRT è il provider di esecuzione con le prestazioni migliori.
TensorRT è in media (35-45% più veloce di DirectML, 20-25% più veloce di CUDA)
CUDA offre miglioramenti moderati rispetto a DirectML (in media 10-12%)
CUDA utilizza una quantità di memoria GPU (VRAM) significativamente maggiore rispetto a TensorRT; prova a ridurre la dimensione del batch se usi CUDA
Download dei componenti
Se selezioni un componente non ancora installato, verrà richiesto di scaricarlo.
Per utilizzare TensorRT o CUDA è necessario scaricare prima i componenti.
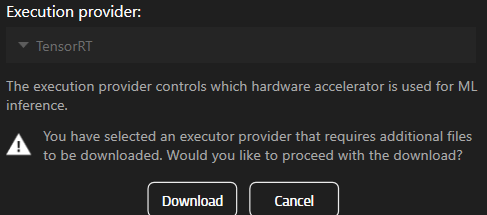
Note: Questa funzione è disponibile solo nella versione 25.2.
Dimensione del batch consigliata
Secondo i nostri test, dimensioni del batch maggiori offrono prestazioni migliori. Consigliamo una dimensione del batch compresa tra 16 e 24 per una configurazione tipica con 2-3 telecamere. Se stai utilizzando contemporaneamente altri software che richiedono risorse grafiche, potrebbe essere utile provare una dimensione del batch inferiore. In definitiva, la dimensione del batch ottimale può dipendere dal tuo flusso di lavoro e dai programmi in esecuzione insieme a Swing Catalyst.
Impostazioni avanzate
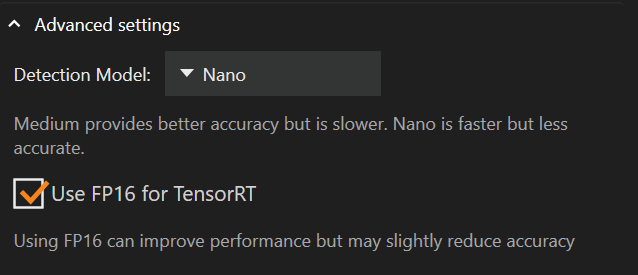
Sotto le impostazioni del provider di esecuzione si trovano le impostazioni avanzate, dove è possibile modificare il modello di rilevamento o abilitare “FP16”.
Passare il modello di rilevamento da Medium a Nano può ridurre l’utilizzo della memoria della scheda grafica e migliorare le prestazioni, a scapito della precisione.
Se hai difficoltà a ottenere un rilevamento soddisfacente, prova a cambiare il modello su Medium, riavvia Swing Catalyst e riprova.
Il modello di rilevamento predefinito è Nano
“FP16 per TensorRT” è disabilitato per impostazione predefinita
FP16
L’utilizzo di FP16 può ridurre l’utilizzo della memoria e migliorare le prestazioni (a scapito della precisione).
Durante i test abbiamo riscontrato che FP16 può migliorare le prestazioni del 20-35%.
Potrebbe inoltre produrre risultati meno coerenti tra le Registrazioni rispetto all’impostazione predefinita FP32. Vale la pena provarlo se riscontri problemi di prestazioni o se la memoria è esaurita.
Confronti tra le prestazioni
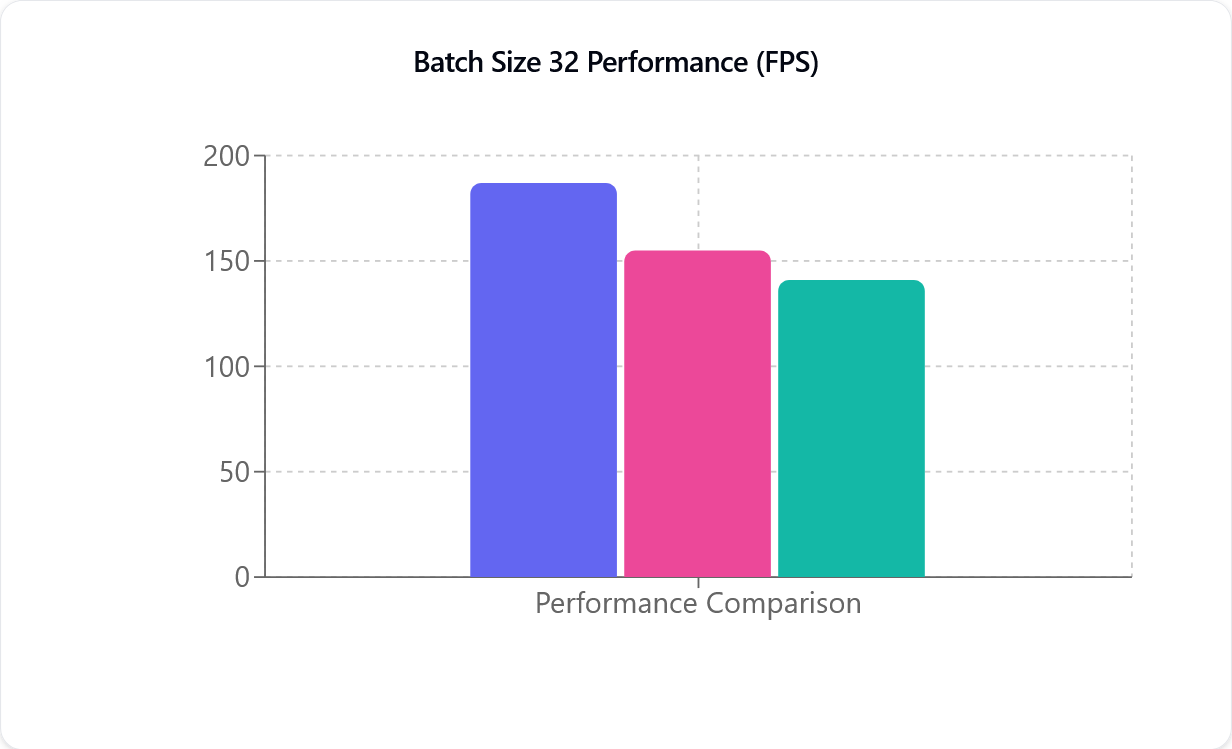
TensorRT (viola), CUDA (rosa) e DirectML (verde), da sinistra a destra. L’asse Y (FPS) indica il numero di Fotogrammi al secondo che il modello di Motion Capture è in grado di elaborare e non è direttamente correlato alla Frequenza fotogrammi della tua telecamera.
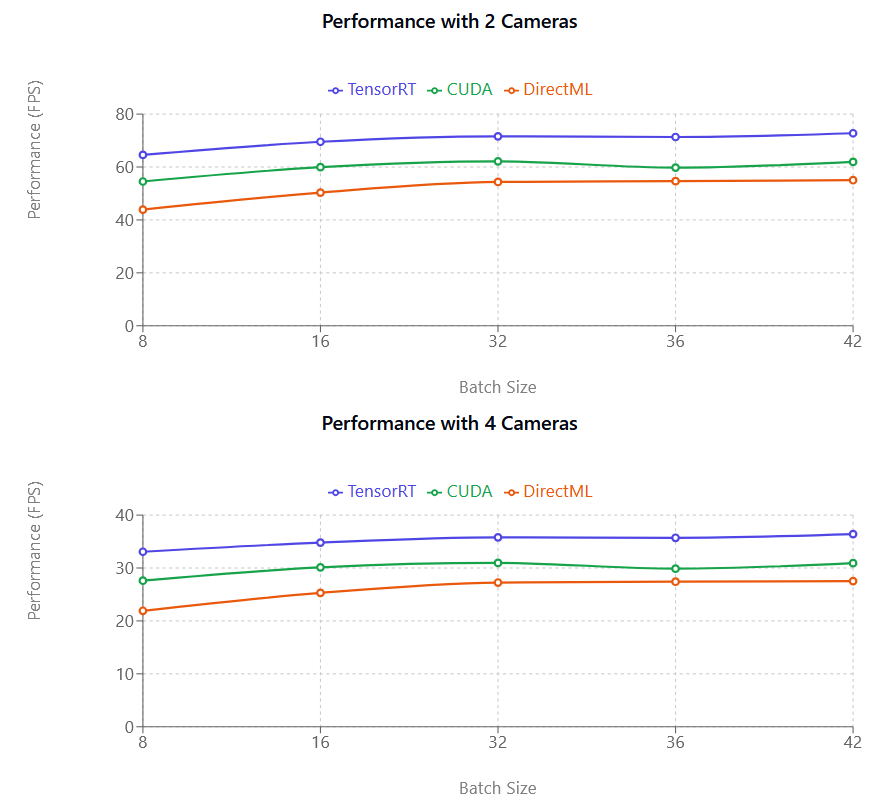
La Metrica delle prestazioni (FPS) indica quanti Fotogrammi al secondo vengono elaborati: un valore più alto corrisponde a un’elaborazione più rapida. Come si può vedere nell’illustrazione precedente, sia CUDA che TensorRT hanno un andamento quasi lineare. Ad esempio, passando da una a due telecamere si osserva quasi la metà delle prestazioni. Questo calo di prestazioni è meno evidente con le schede grafiche NVIDIA più recenti.
Ultimo aggiornamento: 2025-05-16 | Visualizza sul sito di supporto ufficiale