Swing Catalyst モーションキャプチャ設定
はじめに
この記事では、Swing Catalyst におけるモーションキャプチャ機能のセットアップおよび設定方法について説明します。この機能はすべてのライセンスタイプで利用できるわけではありません。詳しくはモーションキャプチャ FAQ をご覧ください。
動作要件
- コンポーネントはコンポーネントディレクトリにインストールする必要があります。
お使いのコンピューターが弊社の PC 仕様推奨条件を満たしている必要があります。特にグラフィックカードが推奨条件を満たしていることが重要です。
設定
モーションキャプチャの設定は、メインの設定メニューの「Video & Capture」セクションから確認できます。ここから実行プロバイダーおよびバッチサイズの選択・変更が可能です。
アクティブ/有効にしているカメラの台数に応じて、バッチサイズは 12 ~ 24 の間を推奨します。
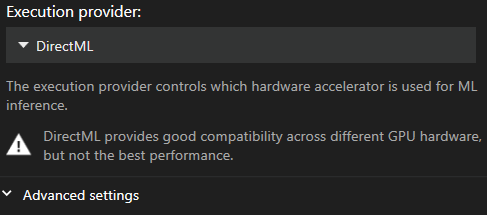
推奨実行プロバイダー
NVIDIA
NVIDIA RTX 3060 以降の GPU -> TensorRT
TensorRT が動作しない場合は CUDA をお試しください
その他のグラフィックカード
- DirectML
デフォルトは DirectML です。最も互換性の高いプロバイダーですが、残念ながら最も処理速度が遅くなります。
ベンチマークテストでは、TensorRT が実行プロバイダーの中で最もパフォーマンスに優れていることが確認されています。
TensorRT は平均して(DirectML より 35~45%、CUDA より 20~25% 高速)
CUDA は DirectML に対して中程度の改善をもたらします(平均 10~12%)
CUDA は TensorRT よりも大幅に多くの GPU メモリ(VRAM)を使用します。CUDA を使用する場合はバッチサイズを小さくしてお試しください
コンポーネントのダウンロード
未インストールのコンポーネントを選択すると、ダウンロードを促すメッセージが表示されます。
TensorRT または CUDA を使用するには、先にコンポーネントをダウンロードする必要があります。
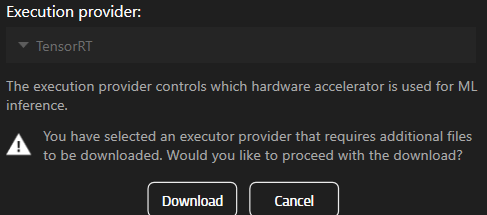
note: この機能はバージョン 25.2 以降でのみ利用可能です。
推奨バッチサイズ
テスト結果によると、バッチサイズが大きいほどパフォーマンスが向上します。一般的な 2~3 台のカメラ構成では、バッチサイズ 16 ~ 24 を推奨します。グラフィックリソースを必要とする他のソフトウェアを同時に使用している場合は、バッチサイズを小さくすると効果的な場合があります。最適なバッチサイズは、作業フローや Swing Catalyst と並行して使用しているプログラムの種類によって異なります。
詳細設定
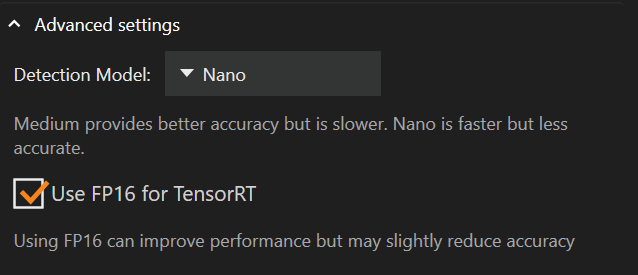
実行プロバイダー設定の下には詳細設定があり、検出モデルの変更や「FP16」の有効化が可能です。
検出モデルを Medium から Nano に変更すると、グラフィックカードのメモリ使用量を抑えてパフォーマンスを向上させることができますが、精度が低下します。
検出精度が十分でない場合は、モデルを Medium に変更し、SwingCatalyst を再起動してから再度お試しください。
デフォルトの検出モデルは Nano です
「TensorRT 用 FP16」はデフォルトで無効(チェックなし)です
FP16
FP16 を使用するとメモリ使用量を削減し、パフォーマンスを向上させることができます(精度は低下します)。
テストでは、FP16 によってパフォーマンスが 20~35% 向上することが確認されています。
また、デフォルトの FP32 と比較して、記録間で結果にばらつきが生じる場合があります。パフォーマンスに問題がある場合やメモリが不足している場合は、試してみる価値があります。
パフォーマンス比較
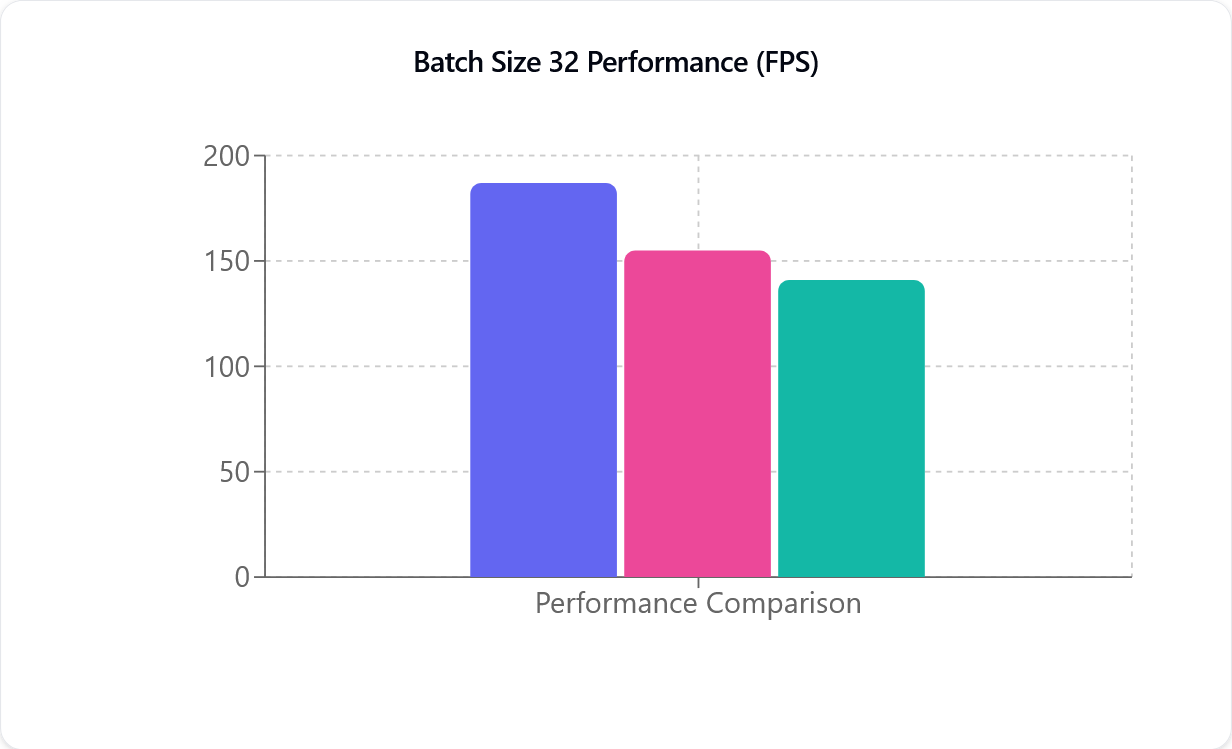
TensorRT(紫)、CUDA(ピンク)、DirectML(緑)、左から右の順。Y 軸(FPS)は、モーションキャプチャモデルが処理できる1秒あたりのフレーム数を示しており、カメラのフレームレートとは直接関係ありません。
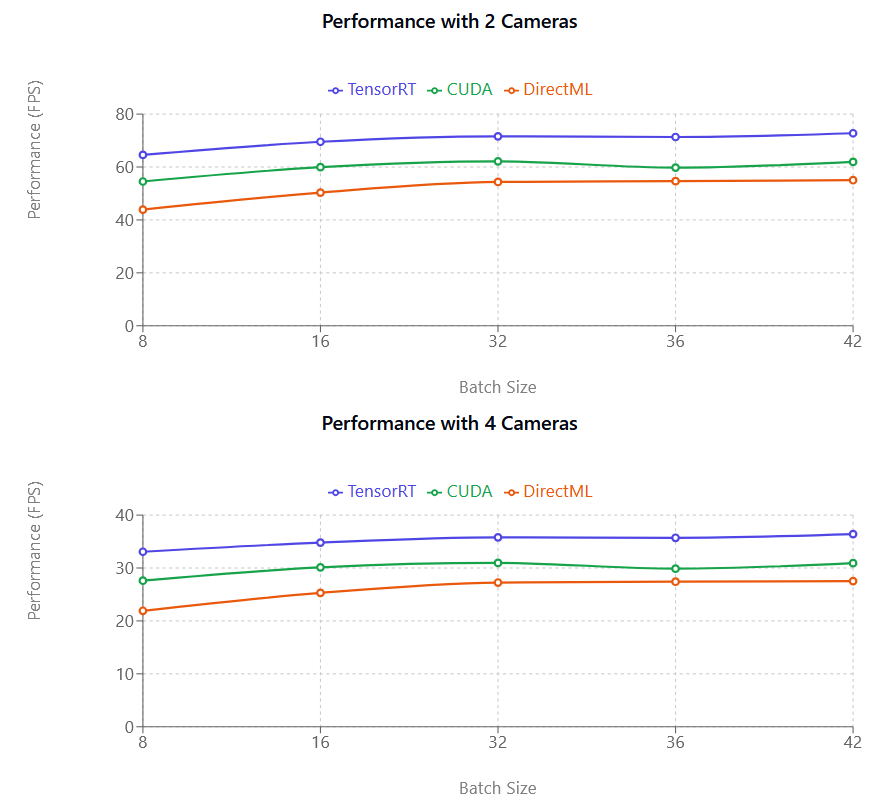
パフォーマンスのメトリクス(FPS)は1秒あたりに処理されるフレーム数を示しており、数値が高いほど処理が速いことを意味します。上の図からわかるように、CUDA と TensorRT はほぼ線形的な特性を示しています。例えば、カメラを 1 台から 2 台に増やすと、パフォーマンスがほぼ半減します。この性能低下は、新しい NVIDIA グラフィックカードではあまり顕著ではありません。
最終更新日: 2025-05-16 | 公式サポートサイトで見る