Configurações de Captura de Movimento do Swing Catalyst
Introdução
Este artigo descreve como configurar e ajustar a funcionalidade de Captura de Movimento no Swing Catalyst. Esta funcionalidade pode não estar disponível para todos os tipos de licença; consulte as nossas Perguntas Frequentes sobre Captura de Movimento para mais informações.
Requisitos
- Os componentes precisam de ser instalados na pasta de componentes.
O seu computador precisa de cumprir as nossas recomendações de especificações para PC; o mais importante é que a placa gráfica cumpra as nossas recomendações.
Configuração
As configurações de Captura de Movimento encontram-se no menu principal de Definições, na secção “Video & Capture”. A partir daqui, pode selecionar ou alterar os fornecedores de execução e o tamanho do lote.
Recomendamos um tamanho de lote entre 12 e 24, dependendo do número de câmeras ativas / habilitadas que tiver.
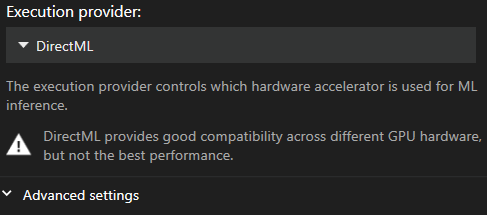
Fornecedor de Execução Recomendado
NVIDIA
GPU NVIDIA RTX 3060 ou mais recente -> TensorRT
Se o TensorRT não funcionar, experimente CUDA
Outras placas gráficas
- DirectML
O padrão é DirectML, pois é o fornecedor mais compatível. Infelizmente, também é o mais lento.
Durante os testes de benchmark, verificámos que o TensorRT é o fornecedor de execução com melhor Desempenho.
O TensorRT é, em média, 35 a 45% mais rápido que o DirectML e 20 a 25% mais rápido que o CUDA
O CUDA oferece melhorias moderadas em relação ao DirectML (10 a 12% em média)
O CUDA utiliza significativamente mais memória GPU (VRAM) do que o TensorRT; tente reduzir o tamanho do lote se usar CUDA
Transferência de componentes
Se selecionar um componente que ainda não está instalado, será solicitado a transferi-lo.
Para utilizar TensorRT ou CUDA, terá de transferir os componentes primeiro.
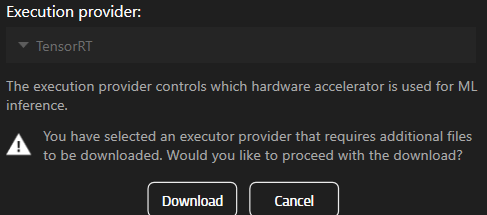
note: Esta funcionalidade está disponível apenas na versão 25.2.
Tamanho de Lote Recomendado
De acordo com os nossos testes, lotes maiores proporcionam melhor Desempenho. Recomendamos um tamanho de lote entre 16 e 24 para uma configuração típica de 2 a 3 câmeras. Se estiver a utilizar outro software em simultâneo que exija recursos gráficos, pode ser vantajoso experimentar um tamanho de lote menor. Em última análise, o melhor tamanho de lote pode depender do seu fluxo de trabalho e do tipo de programas que tem a correr em paralelo com o Swing Catalyst.
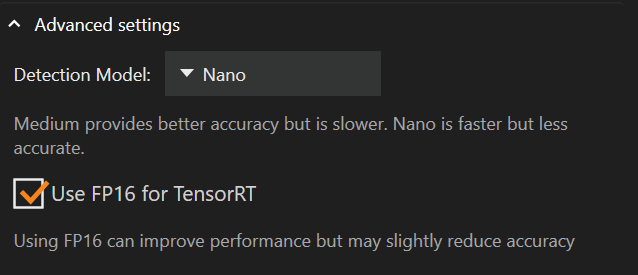
Definições Avançadas
Abaixo das definições do fornecedor de execução encontram-se as definições avançadas, onde pode alterar o modelo de deteção ou ativar o “FP16”.
Alterar o modelo de deteção de Médio para Nano pode reduzir a quantidade de memória utilizada pela placa gráfica e melhorar o Desempenho, à custa da precisão.
Se tiver dificuldades em obter uma deteção satisfatória, tente alterar o modelo para Médio, reinicie o SwingCatalyst e tente novamente.
O modelo de deteção padrão é Nano
“FP16 para TensorRT” está desmarcado por padrão
FP16
A utilização de FP16 pode reduzir o consumo de memória e melhorar o Desempenho (à custa da precisão).
Durante os testes, verificámos que o FP16 pode melhorar o Desempenho entre 20 e 35%.
Pode também produzir resultados menos consistentes entre Gravações do que o FP32 padrão. Pode valer a pena experimentar se tiver problemas de Desempenho ou se estiver a ficar sem memória.
Comparações de Desempenho
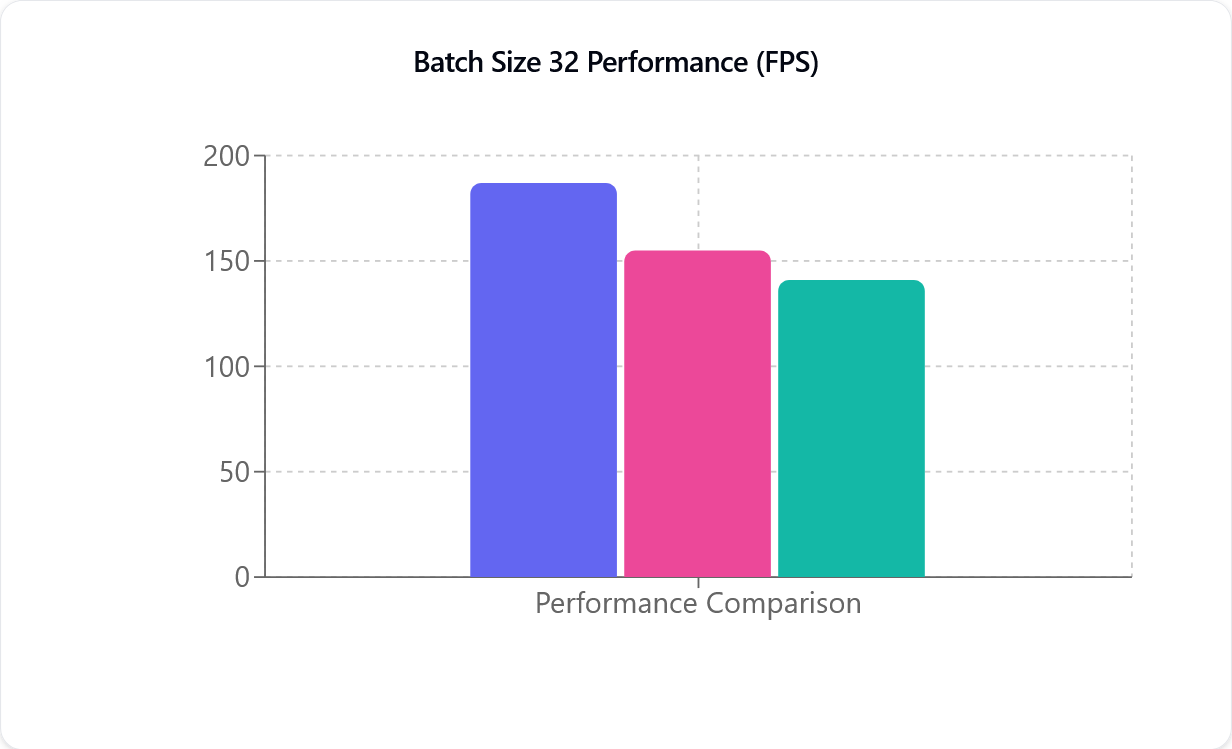
TensorRT (roxo), CUDA (rosa) e DirectML (verde), da esquerda para a direita. O eixo Y (FPS) representa a quantidade de Quadros por Segundo que o modelo de Captura de Movimento é capaz de processar e não está diretamente relacionado com a Taxa de Quadros da sua câmera.
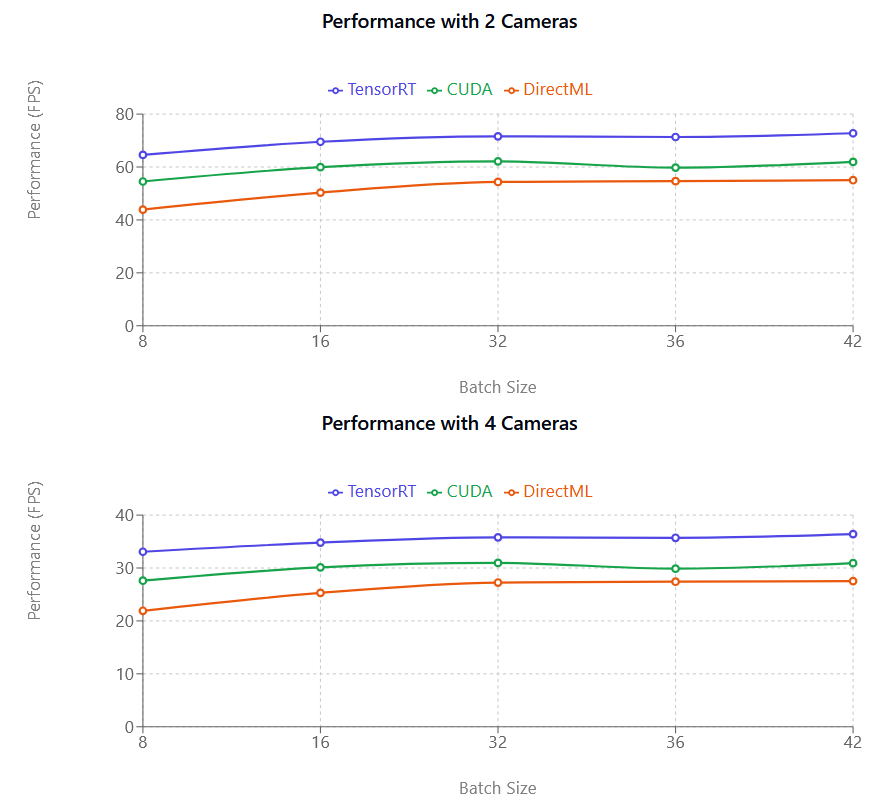
A Métrica de Desempenho (FPS) indica quantos Quadros por Segundo são processados; quanto maior o número, mais rápido será o processamento. Como pode observar na ilustração acima, tanto o CUDA como o TensorRT são quase lineares. Por exemplo, ao passar de uma para duas câmeras, verifica-se quase metade do Desempenho. Esta redução de Desempenho é menos percetível com placas gráficas NVIDIA mais recentes.
Última atualização: 2025-05-16 | Ver no site de suporte oficial