Setări Capturare de Mișcare în Swing Catalyst
Introducere
Acest articol descrie cum să configurați funcționalitatea de Capturare de Mișcare în Swing Catalyst. Este posibil ca această funcție să nu fie disponibilă pentru toate tipurile de licență; consultați Întrebări frecvente despre Capturare de Mișcare pentru mai multe informații.
Cerințe
- Componentele trebuie instalate în directorul de componente.
Computerul dvs. trebuie să îndeplinească recomandările noastre de specificații pentru PC, cel mai important fiind că placa grafică să corespundă recomandărilor noastre.
Configurare
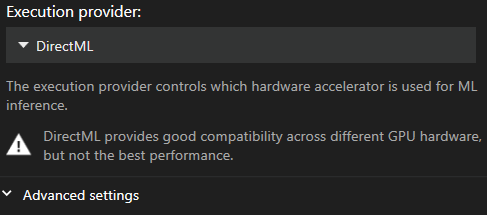
Setările pentru Capturare de Mișcare se găsesc în meniul principal Setări, în secțiunea „Video & Capturare". De aici puteți selecta sau modifica furnizorii de execuție și dimensiunea lotului.
Recomandăm o dimensiune a lotului între 12 și 24, în funcție de numărul de camere active / activate pe care le aveți.
Furnizor de Execuție Recomandat
NVIDIA
GPU NVIDIA RTX 3060 sau mai nou -> TensorRT
Dacă TensorRT nu funcționează, încercați CUDA
Alte plăci grafice
- DirectML
Implicit este DirectML, deoarece este cel mai compatibil furnizor. Din păcate, este și cel mai lent.
În urma testelor de referință, am constatat că TensorRT este cel mai performant dintre furnizorii de execuție.
TensorRT este în medie (cu 35-45% mai rapid decât DirectML, cu 20-25% mai rapid decât CUDA)
CUDA oferă îmbunătățiri moderate față de DirectML (în medie cu 10-12%)
CUDA folosește semnificativ mai multă memorie GPU (VRAM) decât TensorRT; încercați să reduceți dimensiunea lotului dacă folosiți CUDA
Descărcarea componentelor
Dacă selectați o componentă care nu este deja instalată, veți fi solicitat să o descărcați.
Pentru a utiliza TensorRT sau CUDA, va trebui să descărcați mai întâi componentele.
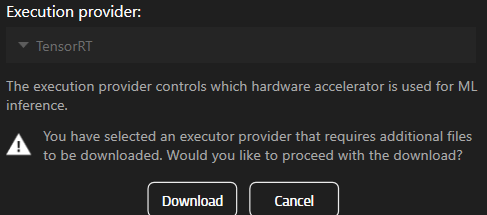
Note: Această funcție este disponibilă doar începând cu versiunea 25.2.
Dimensiunea Recomandată a Lotului
Conform testelor noastre, dimensiunile mai mari ale lotului oferă o Performanță mai bună. Recomandăm o dimensiune a lotului între 16 și 24 pentru o configurație tipică de 2-3 camere. Dacă utilizați în același timp alte programe software care necesită resurse grafice, poate fi benefic să încercați o dimensiune mai mică a lotului. În cele din urmă, dimensiunea optimă a lotului poate depinde de fluxul dvs. de lucru și de tipul de programe pe care le rulați în plus față de Swing Catalyst.
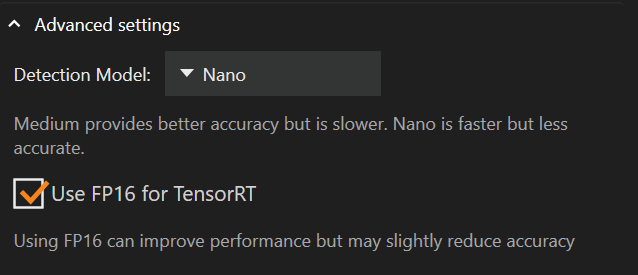
Setări Avansate
Sub setările furnizorului de execuție se află setările avansate, unde puteți schimba modelul de detectare sau activa „FP16".
Schimbarea modelului de detectare din Medium în Nano poate reduce cantitatea de memorie utilizată de placa grafică și poate îmbunătăți Performanța, cu costul preciziei.
Dacă întâmpinați dificultăți în obținerea unei detectări corespunzătoare, încercați să schimbați modelul în Medium, reporniți SwingCatalyst și încercați din nou.
Modelul implicit de detectare este Nano
„FP16 pentru TensorRT" nu este bifat implicit
FP16
Utilizarea FP16 poate reduce consumul de memorie și poate îmbunătăți Performanța (cu costul preciziei).
În urma testelor, am constatat că FP16 poate îmbunătăți Performanța cu 20-35%.
Poate produce, de asemenea, rezultate mai inconsistente între Înregistrări față de valoarea implicită FP32. Merită încercat dacă aveți probleme de Performanță sau dacă rămâneți fără memorie.
Comparații de Performanță
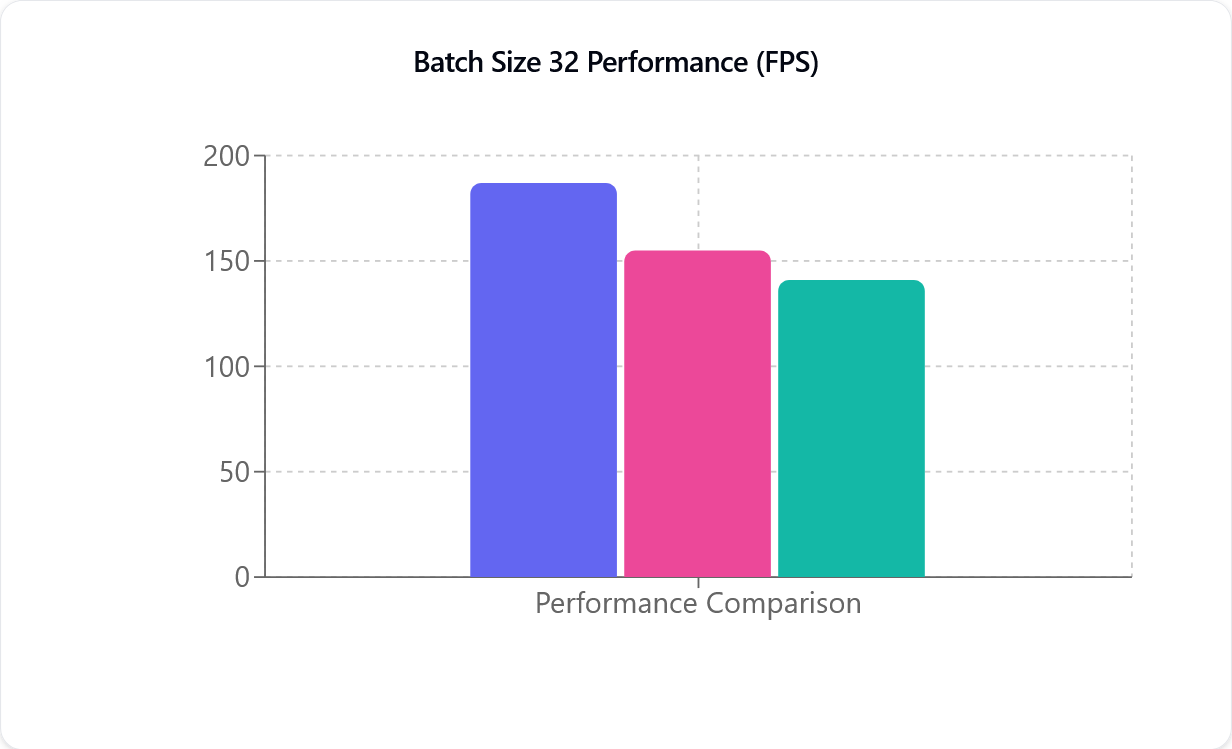
TensorRT (violet), CUDA (roz) și DirectML (verde), de la stânga la dreapta. Axa Y (FPS) reprezintă numărul de Cadre pe Secundă pe care modelul de Capturare de Mișcare este capabil să le proceseze și nu este direct legată de Frecvența Cadru a camerei dvs.
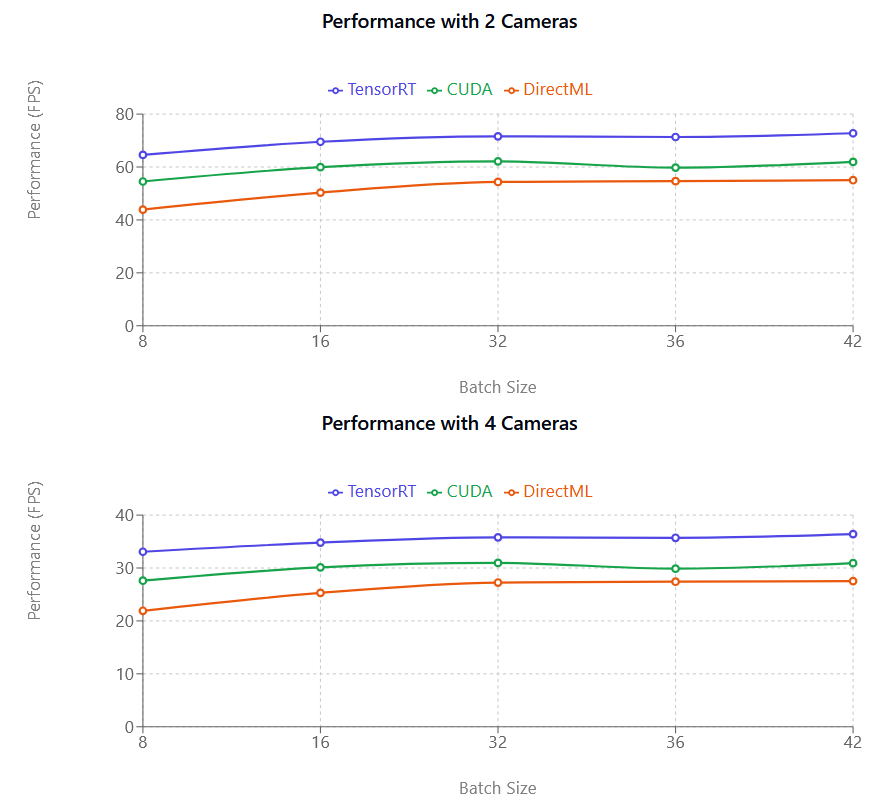
Metrica de Performanță (FPS) reprezintă numărul de Cadre pe Secundă procesate — cu cât numărul este mai mare, cu atât procesarea este mai rapidă. După cum se poate observa în ilustrația de mai sus, atât CUDA, cât și TensorRT sunt aproape liniare. De exemplu, trecând de la una la două camere, Performanța scade aproape la jumătate. Această scădere de Performanță este mai puțin vizibilă în cazul plăcilor grafice NVIDIA mai noi.
Ultima actualizare: 2025-05-16 | Vizualizați pe site-ul oficial de suport