Swing Catalyst Inställningar för Rörelseuppsamling
Introduktion
Den här artikeln beskriver hur du konfigurerar och ställer in funktionen för Rörelseuppsamling i Swing Catalyst. Den här funktionen är kanske inte tillgänglig för alla licenstyper, se vår MoCap-FAQ för mer information.
Krav
- Komponenter måste installeras i komponentkatalogen.
Din dator måste uppfylla våra rekommenderade PC-specifikationer, och viktigast av allt är att grafikkortet uppfyller våra rekommendationer.
Konfiguration
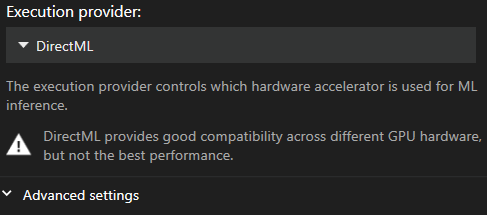
Inställningarna för Rörelseuppsamling finns i huvudmenyn under Inställningar, i avsnittet “Video & Capture”. Härifrån kan du välja eller ändra exekveringsleverantörer och batchstorlek.
Vi rekommenderar en batchstorlek mellan 12 och 24 beroende på hur många aktiva/aktiverade kameror du har.
Rekommenderad exekveringsleverantör
NVIDIA
NVIDIA RTX 3060 eller nyare GPU -> TensorRT
Om TensorRT inte fungerar, prova CUDA
Andra grafikkort
- DirectML
Standard är DirectML eftersom det är den mest kompatibla leverantören. Det är tyvärr också den långsammaste.
Under prestandatester har vi funnit att TensorRT är den mest presterande av exekveringsleverantörerna.
TensorRT är i genomsnitt (35–45 % snabbare än DirectML, 20–25 % snabbare än CUDA)
CUDA erbjuder måttliga förbättringar jämfört med DirectML (10–12 % i genomsnitt)
CUDA använder betydligt mer GPU-minne (VRAM) än TensorRT, försök att minska batchstorleken om du använder CUDA
Nedladdning av komponenter
Om du väljer en komponent som inte redan är installerad kommer du att uppmanas att ladda ned den.
För att använda TensorRT eller CUDA måste du först ladda ned komponenterna.
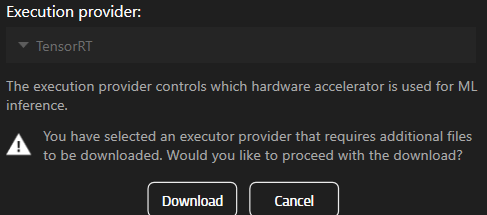
Note: Den här funktionen är endast tillgänglig i version 25.2.
Rekommenderad batchstorlek
Enligt våra tester ger större batchstorlekar bättre prestanda. Vi rekommenderar en batchstorlek mellan 16 och 24 för en typisk setup med 2–3 kameror. Om du använder annan programvara samtidigt som kräver grafikresurser kan det vara fördelaktigt att prova en lägre batchstorlek. I slutändan kan den bästa batchstorleken bero på ditt arbetsflöde och vilka typer av program du kör parallellt med Swing Catalyst.
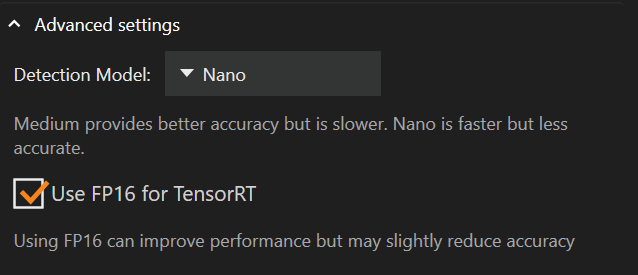
Avancerade inställningar
Under inställningarna för exekveringsleverantör finns de avancerade inställningarna där du kan ändra detekteringsmodell eller aktivera “FP16”.
Att byta detekteringsmodell från Medium till Nano kan minska hur mycket minne ditt grafikkort använder och förbättra prestandan, på bekostnad av noggrannhet.
Om du har svårt att få en tillfredsställande detektering, försök att byta modell till Medium, starta om SwingCatalyst och prova igen.
Standarddetekteringsmodellen är Nano
“FP16 för TensorRT” är som standard inte ikryssad
FP16
Att använda FP16 kan minska minnesanvändningen och förbättra prestandan (på bekostnad av noggrannhet).
Under testning har vi funnit att FP16 kan förbättra prestandan med 20–35 %.
Det kan också ge mer inkonsekvent resultat mellan Inspelningar jämfört med standard FP32. Det kan vara värt att prova om du har prestandaproblem eller om du håller på att få slut på minne.
Prestandajämförelser
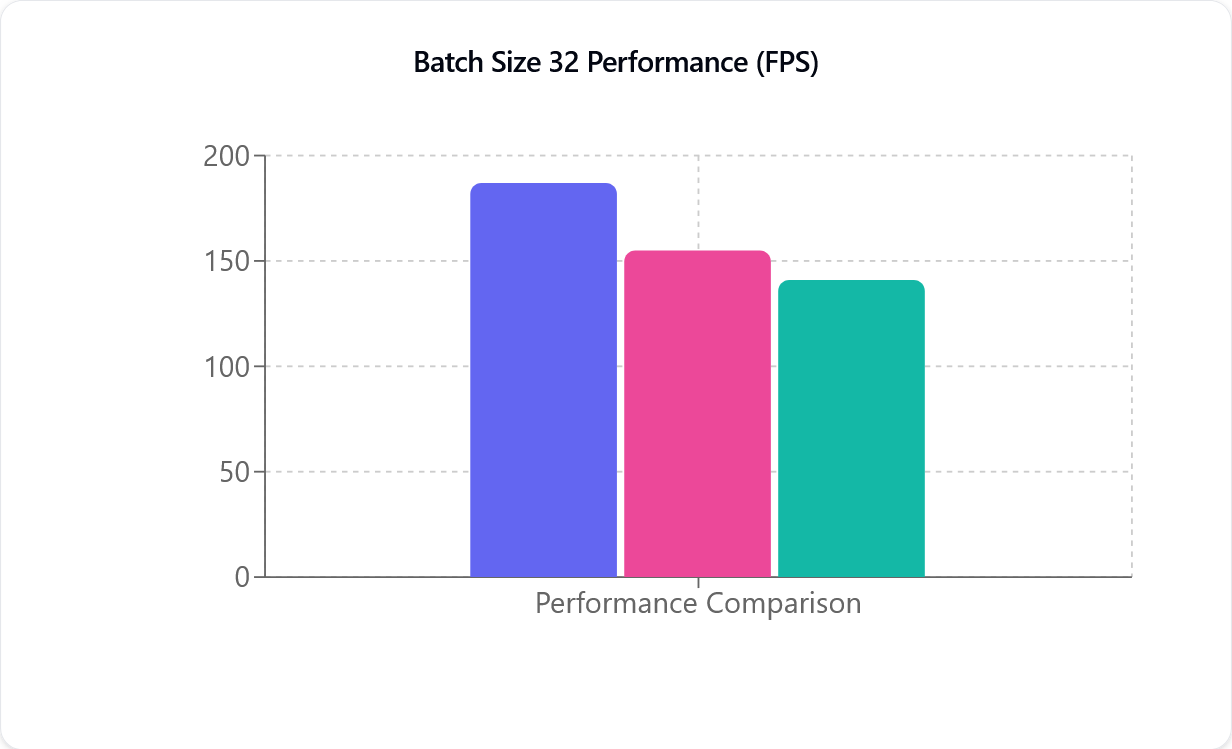
TensorRT (lila), CUDA (rosa) och DirectML (grön), från vänster till höger. Y-axeln (FPS) är antalet ramar per sekund som rörelseuppsamlingsmodellen kan bearbeta och är inte direkt kopplat till din kameras bildhastighet.
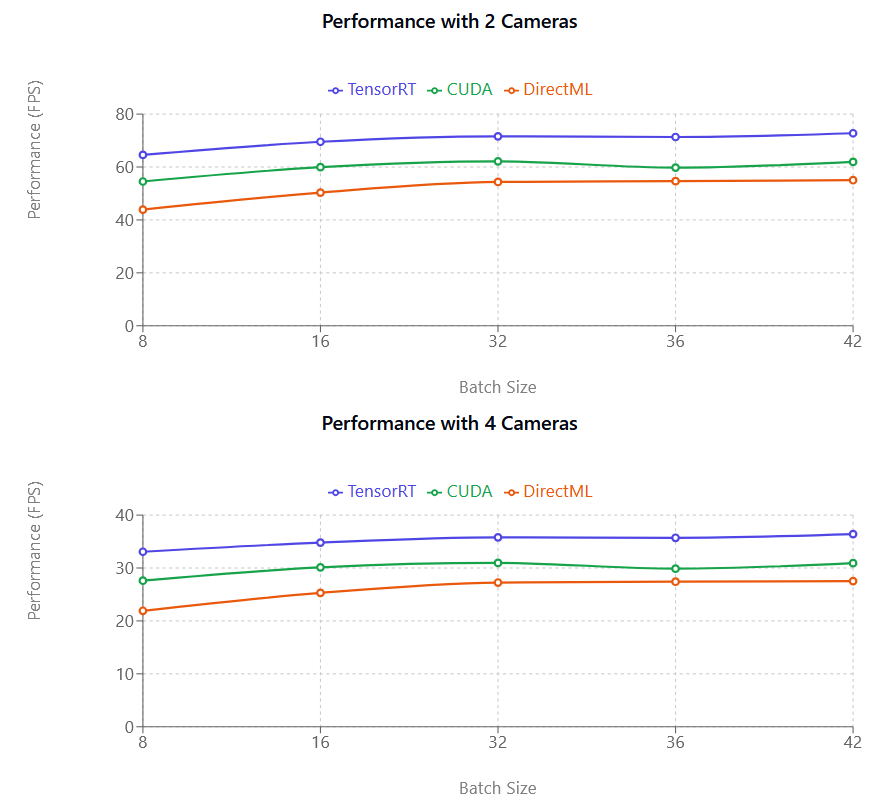
Prestandamåttet (FPS) är hur många ramar per sekund som bearbetas – ju högre siffra, desto snabbare bearbetning. Som du kan se i illustrationen ovan är både CUDA och TensorRT nästan linjära. Om du till exempel går från en till två kameror ser du nästan en halvering av prestandan. Denna prestandaförsämring är mindre märkbar med nyare NVIDIA-grafikkort.
Senast uppdaterad: 2025-05-16 | Visa på officiell supportsida