การตั้งค่า Motion Capture ของ Swing Catalyst
บทนำ
บทความนี้อธิบายวิธีการเตรียมตัวและกำหนดค่าฟังก์ชัน Motion Capture ภายใน Swing Catalyst ฟีเจอร์นี้อาจไม่พร้อมใช้งานสำหรับใบอนุญาตทุกประเภท โปรดดูคำถามที่พบบ่อยเกี่ยวกับ Motion Capture สำหรับข้อมูลเพิ่มเติม
ข้อกำหนด
- ต้องติดตั้งคอมโพเนนต์ลงในไดเรกทอรีคอมโพเนนต์
คอมพิวเตอร์ของคุณต้องตรงตามคำแนะนำข้อกำหนด PC ของเรา โดยเฉพาะอย่างยิ่งการ์ดจอต้องตรงตามคำแนะนำของเรา
การกำหนดค่า
การตั้งค่า Motion Capture สามารถพบได้จากเมนูการตั้งค่าหลักในส่วน “Video & Capture” จากที่นี่คุณสามารถเลือกหรือเปลี่ยน execution provider และขนาด batch ได้
เราแนะนำขนาด batch ระหว่าง 12 ถึง 24 ขึ้นอยู่กับจำนวนกล้องที่ใช้งานอยู่ / เปิดใช้งาน
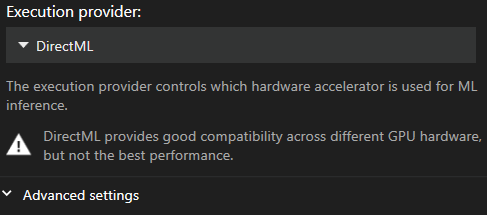
Execution Provider ที่แนะนำ
NVIDIA
GPU รุ่น NVIDIA RTX 3060 หรือใหม่กว่า -> TensorRT
หาก TensorRT ใช้งานไม่ได้ ให้ลอง CUDA
การ์ดจออื่น ๆ
- DirectML
ค่าเริ่มต้นคือ DirectML เนื่องจากเป็น provider ที่รองรับการใช้งานได้กว้างที่สุด แต่น่าเสียดายที่มันช้าที่สุดด้วย
จากการทดสอบประสิทธิภาพ เราพบว่า TensorRT มีประสิทธิภาพสูงที่สุดในบรรดา execution provider ทั้งหมด
TensorRT เร็วกว่า DirectML โดยเฉลี่ย 35-45% และเร็วกว่า CUDA โดยเฉลี่ย 20-25%
CUDA มีประสิทธิภาพดีกว่า DirectML ในระดับปานกลาง (เฉลี่ย 10-12%)
CUDA ใช้หน่วยความจำ GPU (VRAM) มากกว่า TensorRT อย่างมีนัยสำคัญ โปรดลองลดขนาด batch หากคุณใช้ CUDA
การดาวน์โหลดคอมโพเนนต์
หากคุณเลือกคอมโพเนนต์ที่ยังไม่ได้ติดตั้ง ระบบจะแจ้งให้ดาวน์โหลด
หากต้องการใช้ TensorRT หรือ CUDA คุณต้องดาวน์โหลดคอมโพเนนต์ก่อน
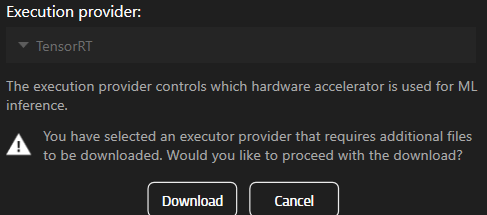
note: ฟีเจอร์นี้พร้อมใช้งานในเวอร์ชัน 25.2 เท่านั้น
ขนาด Batch ที่แนะนำ
จากการทดสอบของเรา ขนาด batch ที่ใหญ่กว่าจะให้ประสิทธิภาพที่ดีกว่า เราแนะนำขนาด batch ระหว่าง 16 ถึง 24 สำหรับการเตรียมตัวด้วยกล้อง 2-3 ตัวทั่วไป หากคุณใช้ซอฟต์แวร์อื่นพร้อมกันที่ต้องการทรัพยากรกราฟิก การลองใช้ขนาด batch ที่เล็กลงอาจเป็นประโยชน์ ท้ายที่สุดแล้ว ขนาด batch ที่ดีที่สุดอาจขึ้นอยู่กับขั้นตอนการทำงานของคุณและโปรแกรมประเภทใดที่คุณรันควบคู่ไปกับ Swing Catalyst
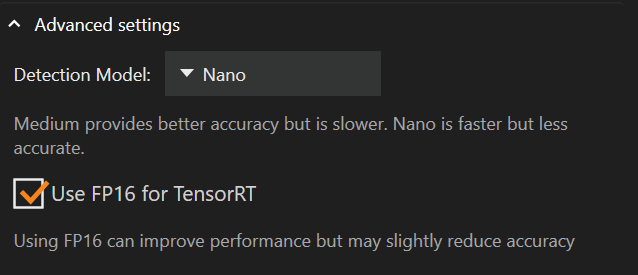
การตั้งค่าขั้นสูง
ด้านล่างการตั้งค่า execution provider คือการตั้งค่าขั้นสูง ซึ่งคุณสามารถเปลี่ยนโมเดลการตรวจจับหรือเปิดใช้งาน “FP16” ได้
การเปลี่ยนโมเดลการตรวจจับจาก Medium เป็น Nano สามารถลดปริมาณหน่วยความจำที่การ์ดจอของคุณใช้และปรับปรุงประสิทธิภาพได้ แต่แลกมาด้วยความแม่นยำที่ลดลง
หากคุณมีปัญหาในการตรวจจับที่ดี ให้ลองเปลี่ยนโมเดลเป็น Medium แล้วรีสตาร์ท Swing Catalyst และลองอีกครั้ง
โมเดลการตรวจจับเริ่มต้นคือ Nano
“FP16 for TensorRT” จะไม่ถูกเลือกไว้โดยค่าเริ่มต้น
FP16
การใช้ FP16 สามารถลดการใช้หน่วยความจำและปรับปรุงประสิทธิภาพได้ (แต่แลกมาด้วยความแม่นยำที่ลดลง)
จากการทดสอบ เราพบว่า FP16 สามารถปรับปรุงประสิทธิภาพได้ 20-35%
นอกจากนี้ยังอาจให้ผลลัพธ์ที่ไม่สม่ำเสมอระหว่างการบันทึกมากกว่าค่าเริ่มต้น FP32 อาจคุ้มค่าที่จะลองหากคุณมีปัญหาด้านประสิทธิภาพหรือหน่วยความจำไม่เพียงพอ
การเปรียบเทียบประสิทธิภาพ
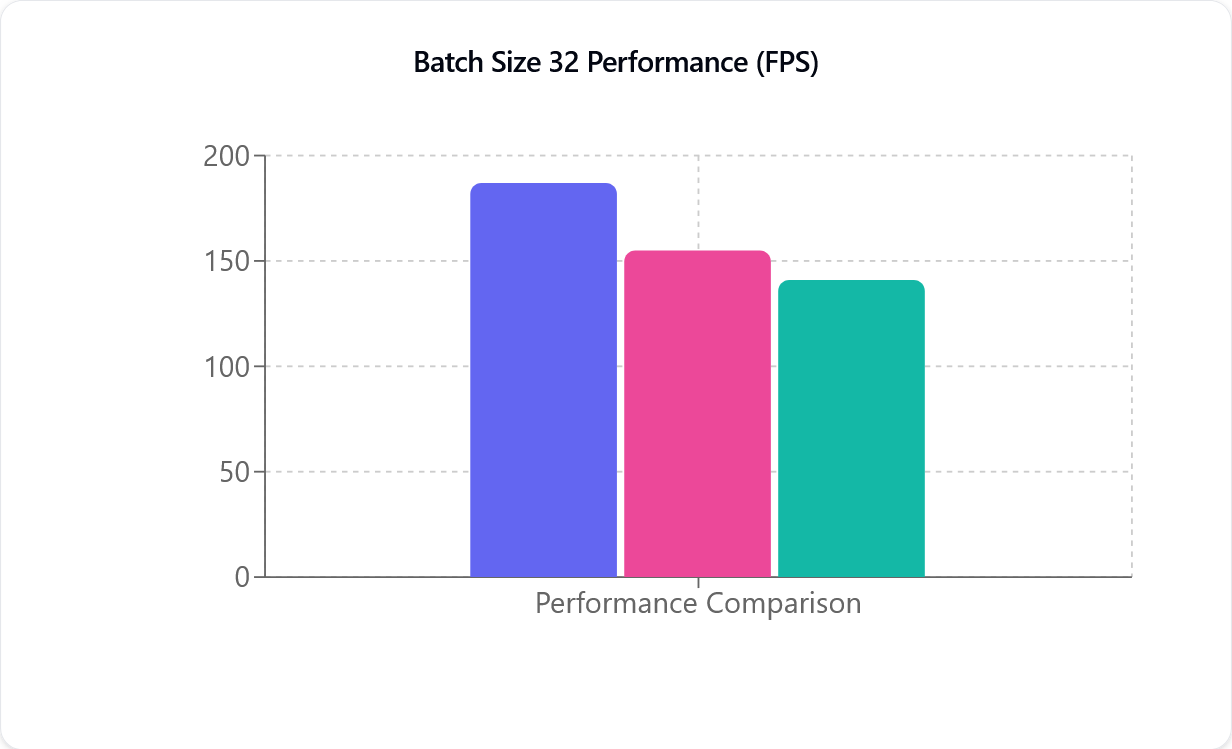
TensorRT (สีม่วง), CUDA (สีชมพู), และ DirectML (สีเขียว), จากซ้ายไปขวา แกน Y (FPS) คือจำนวนเฟรมต่อวินาทีที่โมเดล Motion Capture สามารถประมวลผลได้ และไม่ได้เกี่ยวข้องโดยตรงกับอัตราเฟรมของกล้องคุณ
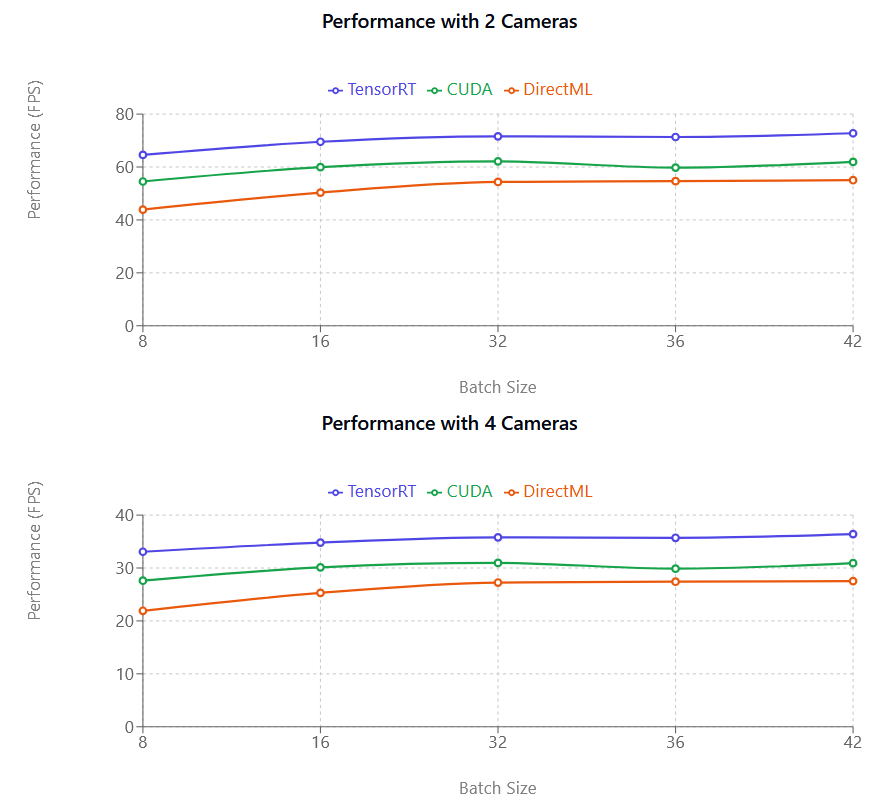
เมตริกประสิทธิภาพ (FPS) คือจำนวนเฟรมต่อวินาทีที่ถูกประมวลผล ยิ่งตัวเลขสูงยิ่งประมวลผลได้เร็วขึ้น ดังที่เห็นในภาพประกอบด้านบน ทั้ง CUDA และ TensorRT มีความสัมพันธ์แบบเกือบเส้นตรง เช่น เมื่อเพิ่มจากกล้องหนึ่งตัวเป็นสองตัว ประสิทธิภาพจะลดลงเกือบครึ่งหนึ่ง ผลกระทบด้านประสิทธิภาพนี้จะสังเกตเห็นได้น้อยลงกับการ์ดจอ NVIDIA รุ่นใหม่กว่า
อัปเดตล่าสุด: 2025-05-16 | ดูบนเว็บไซต์ฝ่ายสนับสนุนทางการ