Налаштування Захоплення руху у Swing Catalyst
Вступ
У цій статті описано, як налаштувати та сконфігурувати функцію Захоплення руху у Swing Catalyst. Ця функція може бути недоступна для всіх типів ліцензій — будь ласка, перегляньте наші Поширені запитання щодо Захоплення руху для отримання додаткової інформації.
Вимоги
- Компоненти необхідно встановити до директорії компонентів.
Ваш комп’ютер повинен відповідати нашим рекомендованим технічним вимогам до ПК; найважливіше — щоб відеокарта відповідала нашим рекомендаціям.
Конфігурація
Налаштування Захоплення руху знаходяться в головному меню «Параметри» у розділі «Відео та Захоплення». Тут можна вибрати або змінити постачальників виконання та розмір пакету.
Ми рекомендуємо розмір пакету від 12 до 24 залежно від кількості активних / увімкнених камер.
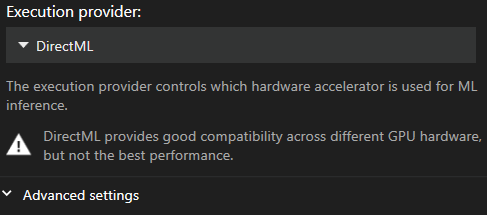
Рекомендований постачальник виконання
NVIDIA
GPU NVIDIA RTX 3060 або новіший -> TensorRT
Якщо TensorRT не працює, спробуйте CUDA
Інші відеокарти
- DirectML
За замовчуванням використовується DirectML, оскільки він є найбільш сумісним постачальником. Проте він, на жаль, є найповільнішим.
Під час тестування продуктивності ми з’ясували, що TensorRT є найефективнішим серед постачальників виконання.
TensorRT в середньому швидший (на 35–45% швидший за DirectML, на 20–25% швидший за CUDA)
CUDA забезпечує помірне покращення порівняно з DirectML (в середньому на 10–12%)
CUDA використовує значно більше відеопам’яті (VRAM), ніж TensorRT — будь ласка, спробуйте зменшити розмір пакету, якщо використовуєте CUDA
Завантаження компонентів
Якщо ви виберете компонент, який ще не встановлено, вам буде запропоновано завантажити його.
Для використання TensorRT або CUDA необхідно спочатку завантажити відповідні компоненти.
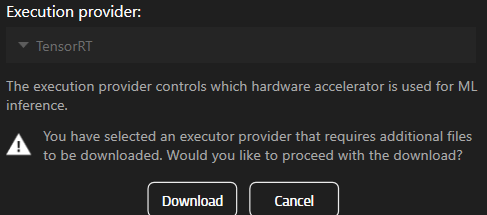
note: Ця функція доступна лише у версії 25.2.
Рекомендований розмір пакету
Згідно з нашим тестуванням, більший розмір пакету забезпечує кращу продуктивність. Для типового налаштування з 2–3 камерами ми рекомендуємо розмір пакету від 16 до 24. Якщо ви одночасно використовуєте інше програмне забезпечення, що потребує графічних ресурсів, може бути доцільним спробувати менший розмір пакету. Зрештою, оптимальний розмір пакету може залежати від вашого робочого процесу та того, які програми запущені разом із Swing Catalyst.
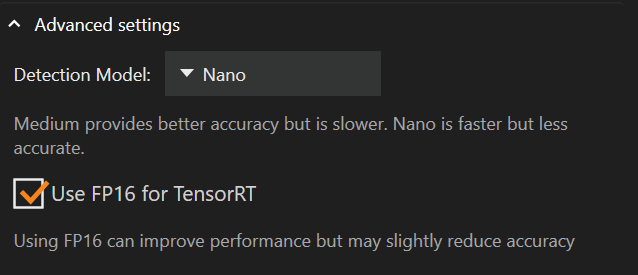
Розширені налаштування
Нижче налаштувань постачальника виконання знаходяться розширені налаштування, де можна змінити модель виявлення або увімкнути «FP16».
Зміна моделі виявлення з Medium на Nano може зменшити обсяг використовуваної відеопам’яті та підвищити продуктивність, але за рахунок точності.
Якщо вам не вдається отримати задовільне виявлення, спробуйте змінити модель на Medium, перезапустіть Swing Catalyst і спробуйте знову.
За замовчуванням використовується модель виявлення Nano
«FP16 для TensorRT» за замовчуванням не увімкнено
FP16
Використання FP16 може зменшити використання пам’яті та підвищити продуктивність (за рахунок точності).
Під час тестування ми з’ясували, що FP16 може підвищити продуктивність на 20–35%.
Воно також може давати менш стабільні результати між Записами порівняно зі стандартним FP32. Варто спробувати, якщо у вас виникають проблеми з продуктивністю або закінчується пам’ять.
Порівняння продуктивності
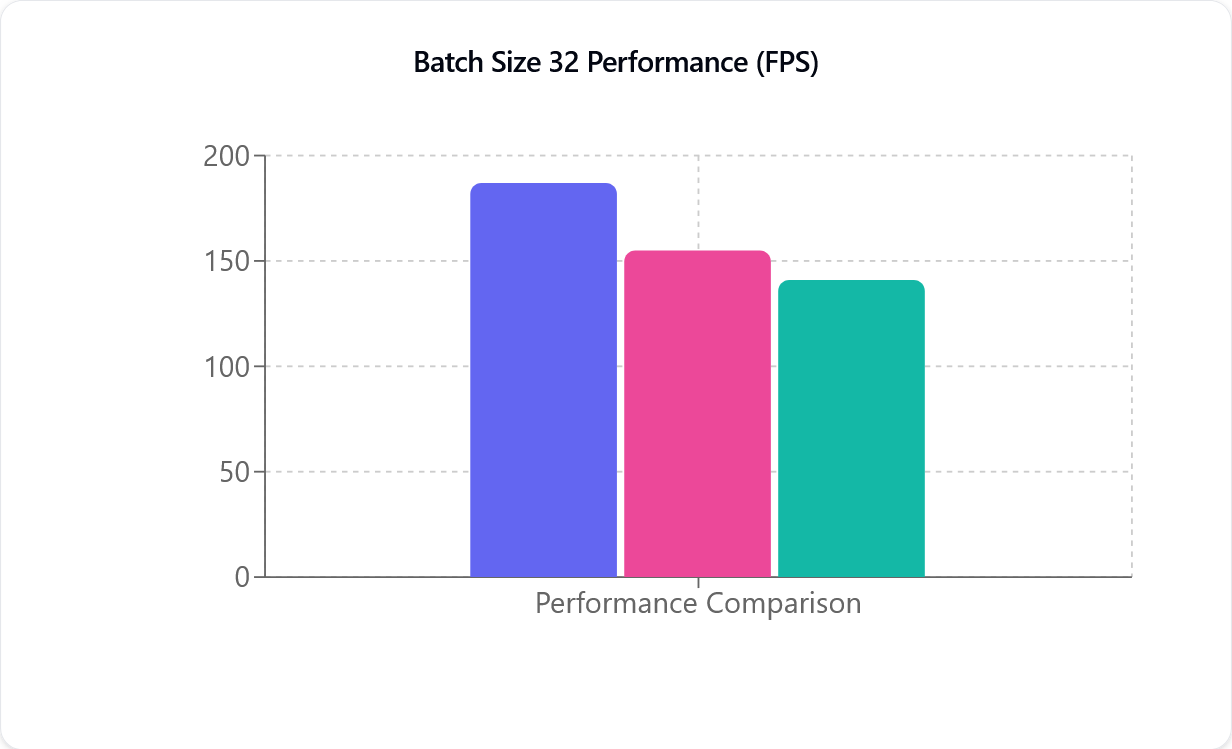
TensorRT (фіолетовий), CUDA (рожевий) і DirectML (зелений), зліва направо. Вісь Y (FPS) — це кількість кадрів на секунду, яку здатна обробляти модель Захоплення руху, і вона не пов’язана безпосередньо з частотою кадрів вашої камери.
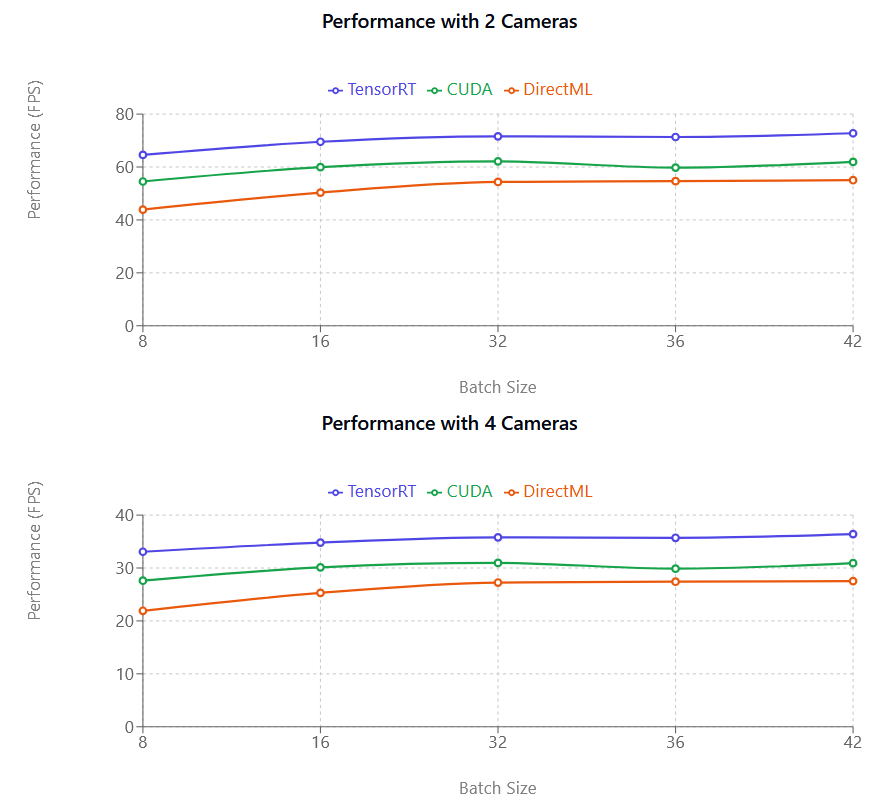
Метрика продуктивності (FPS) — це кількість кадрів на секунду, що обробляються: що більше число, то швидше відбувається обробка. Як видно з наведеної ілюстрації, CUDA і TensorRT мають майже лінійну залежність. Наприклад, при переході від однієї до двох камер продуктивність зменшується приблизно вдвічі. Це зниження продуктивності менш помітне на новіших відеокартах NVIDIA.
Останнє оновлення: 2025-05-16 | Переглянути на офіційному сайті підтримки